


目次
はじめに
2025年DeepSeek-R1というAIモデルが公開され世間を賑わせました。軽い!安い!賢い!と話題になっていますがDeepSeekの魅力の本質はそこではなく、そこにたどり着いたプロセス自体が革新的である点にあります。
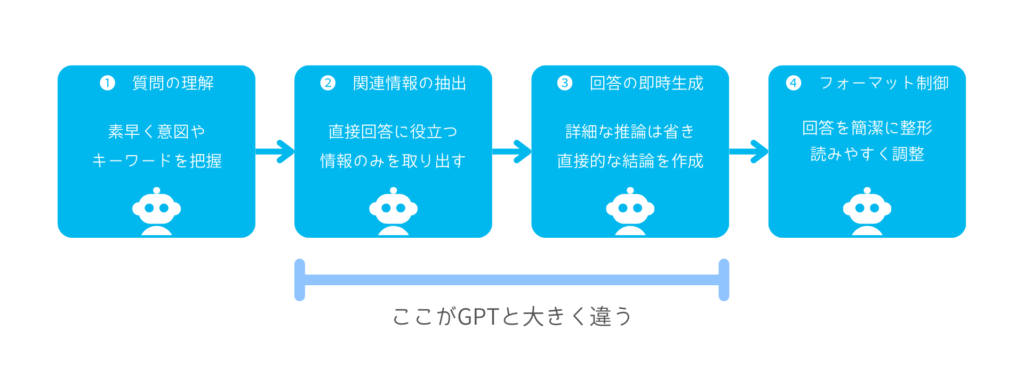
従来のAI開発では、問題解決の途中過程を細かく評価するために、膨大なコストと複雑な技術が必要とされていました。しかし、DeepSeek-R1は最終結果だけを評価するというシンプルな方法に転換することで、従来の常識を覆し、効率的かつ革新的なAIモデルを実現しました。この新たなアプローチこそが、今後のAI技術の発展において大きな可能性を秘めているのです。
今回はDeepSeekの実際の論文を元に分かりやすく説明していきます。
https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
DeepSeek-R1の革新的なポイント
話題のコストパフォーマンス

一般的に、最先端のAIモデルを開発・トレーニングするためには、数千万ドルにも上る莫大な予算と、膨大な計算リソースが必要とされます。しかし、DeepSeek-R1は「たった500万ドル」という比較的低予算で、他の有名モデルに匹敵する性能を実現しています。
この低コストの背景には、単に経済的な効率だけでなく、AIの学習方法自体に革新があったことが挙げられます。つまり、従来の複雑で手間のかかるプロセスを省略することで、トレーニング全体のコストを大幅に削減することに成功したのです。
結果だけで評価するシンプルな学習方法
従来の方法:中間プロセスの評価
従来のAIトレーニングではAIが「どのような推論プロセスを経て最終的な答えにたどり着いたか」という中間過程を評価する手法が一般的でした。
中間過程を評価する理由は、最終的な答えだけを見ても、途中で間違った判断や不適切な推論があれば、その答えの信頼性が低くなってしまうと考えられていたからです。
しかし、このアプローチは手間と計算資源が必要になり、結果としてトレーニングコストが高くなるという問題点がありました。
例をあげてみます。先生は「この問題『25 + 37 = ?』を解いてみてください。計算の過程も詳しく書いてください。」といいます。
生徒は以下のように解答します:
- 25を20と5に分ける。
- 37を30と7に分ける。
- 20と30を足して50、5と7を足して12。
- 最後に50と12を足して62。
先生は、生徒がどのような手順で計算したか、各ステップが正しいかどうかを丁寧に確認します。途中でもし誤った計算をしていたら、最終結果が偶然正しくても「プロセスに問題がある」と判断されるかもしれません。この方法は、答えにたどり着く過程そのものの正確性を重視していますが、その分、評価に時間や手間がかかります。
DeepSeek-R1のアプローチ:最終結果のみで評価

DeepSeek-R1はここで一転、最終的な答えだけを評価するというシンプルな方法を採用しました。
つまり、AIが問題に対してどのような過程を経たかは一切チェックせず、出された答えが正しいかどうかだけに注目します。
先生は「この問題『25 + 37 = ?』を解いて答えだけを書いてください。」といいます。
生徒は、途中の詳細な計算過程は省略して、最終結果「62」だけを書きます。
先生は、解答の途中の計算プロセスを一切チェックせず、最終的な答え「62」が正しいかどうかだけを確認します。たとえ生徒がどのような独自の考え方で計算したとしても、結果が正しければ評価は高くなります。この方法は、計算過程の詳細な検証にかかる手間を省き、正しい答えだけに注目するシンプルな評価方法です。
この手法は、一見すると「途中の考え方を無視してしまうのでは?」と疑問に思われるかもしれません。しかし、実際にトレーニング結果を見てみると、AIは非常に高い性能を発揮しました。
厳密にはここまで単調な話ではなく、強化学習にてGRPOという手法が採用されたことによる性能向上があるのですが、本記事は非技術者向けであることをご了承ください。
途中プロセスを見ないにもかかわらず得られた成長
DeepSeek-R1では、最終的な結果のみを正否の基準としているにもかかわらず、AI自体が自律的に「気づき」を得ることが確認されました。
具体的には、トレーニング中にAIは出力結果の正誤を通じて、自分の内部でどのような誤りがあったかを暗黙的に学習し、次第に自己修正する能力を高めていきました。
実際にDeepSeek学習段階の√(a − √(a+x)) = xを解く問題で以下のような挙動を確認したといいます(論文9ページ目より)。
Wait, wait. Wait. That’s an aha moment I can flag here.
Let’s reevaluate this step-by-step to identify if the correct sum can be · · ·
(訳)待て、待て。これはとんでもない発見や。正しい合計が出るかどうかを確認するために、ステップバイステップでもう一度見直してみよう。
まさに人間が行っているかのような思考が見られます。
DeepSeek-R1の凄さはまさにここにあり、学習コストを抑えて高いパフォーマンスを発揮することを可能にしたのです。
業界への波及効果
オープンソースによる汎用性
DeepSeek-R1はMITライセンスでオープンソースとして公開されています。
オープンソースであることにより、企業や個人開発者が自らのニーズに合わせたカスタマイズを行いやすくなるため、医療、金融、製造業など多岐にわたる分野での応用が期待されます。
株価を動かすほどの影響力
学習に必要なGPUリソースを大幅に削減できることで、必要コストが下がる可能性が示唆され、業界内外で「GPU需要が落ちるのでは?」との憶測が飛び交いました。
この憶測が広がった結果、NVIDIAのデータセンター向けGPUを中心とする製品に対して、需要が減少するのではないかという不安が市場に波及し、2025年1月24日の終値142.62ドルから1月27日には118.42ドルまで約17%も下落するという、株価暴落が起こりました。
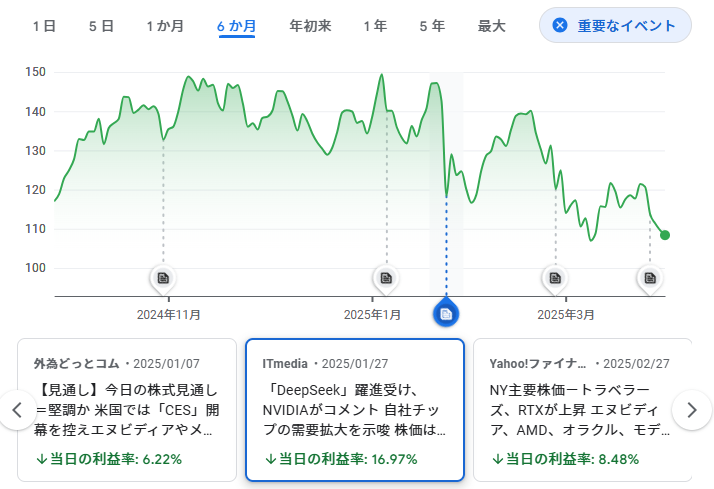
この動きは、DeepSeekへの市場の過剰反応とも言えるでしょう。
過去、NANDフラッシュメモリの高密度化と製造効率の向上により、1チップあたりに必要なメモリ量が減少し、単価も下がるという技術革新が起こりました。当初、一部の投資家は「低コスト化が収益の減少につながるのではないか」と懸念し、主要メーカーの株価が一時的に下落する局面も見られました。しかし、実際には低価格かつ高性能なメモリが普及することで、スマートフォンやクラウドサービス、各種デジタル機器への採用が急増。結果として、従来の予想を覆し、メモリ市場全体は大きく拡大しました。
この例と同様に、GPUについても、DeepSeekのように1回あたりの必要リソースが削減される一方で、その低コスト性と高性能化が多様なユーザー層への普及を促し、結果として全体の市場規模が拡大する可能性があります。
プライバシーへの懸念
中国国内サーバーに保存されるデータの問題

Web上のDeepSeekは、中国のサーバーにユーザーデータを保存しているため、注意が必要です。中国ではサーバ内のデータが必要と判断されれば、政府に提供される可能性があります。たとえば、企業の機密情報やソースコード、個人情報などが、ユーザーの意図せず中国政府の監視対象となるリスクが懸念されます。
オプトアウト機能の不在とデータ利用の透明性
ChatGPTやGeminiなどの一部サービスでは、ユーザーが自らの入力データを学習に使用しないように設定できるオプトアウト機能が提供されています。しかし、DeepSeekの場合、現時点ではそのような機能が用意されていないため、入力された情報が自由に学習データとして利用される可能性があります。これにより、企業が取り扱う重要な情報や個人データが、意図せず学習プロセスに組み込まれるリスクも考えられます。
オンプレミスでの運用と蒸留モデルの活用
DeepSeekは企業内部のオンプレミス環境に導入することで、データを社内に留める運用も可能です。オンプレミスで運用することで、外部クラウドにデータが送信されるリスクを大幅に低減でき、プライバシー面での安心度が向上します。ただし、初期セットアップやメンテナンス時にDeepSeek側との通信が発生する可能性があるため、その範囲や内容について事前に十分な確認が必要です。
まとめ
DeepSeekは「安くトレーニングできた」と持ち上げられがちですが、実はその裏にある学習方法こそが真の議論のポイントです。従来のAIトレーニングでは、途中の細かい工程まで評価するために多くのコストと計算リソースが必要でした。しかし、DeepSeekは最終結果だけを評価するシンプルな手法を採用することで、無駄な計算を省き、効率的に学習を進めることが可能になりました。
また、オープンソースで公開されているため、幅広い分野での応用も期待され、今後の技術発展に大きな影響を与えることでしょう。
一方で、DeepSeekはデータを中国のサーバーに保存しているため、プライバシーへの懸念もあります。企業がこの技術を導入する際には、どのデータがどこに保存され、どのように利用されるのかをしっかりと確認し、慎重なアプローチを取ることが大切です。技術の進歩とともに、プライバシー保護のための対策も合わせて検討することが、今後の成功には欠かせないと言えるでしょう。

