


最新のAI技術であるLLM(大規模言語モデル)は、まるで人間と会話しているかのような体験を提供し、注目を集めています。しかし、その仕組みについて理解している人はまだまだ少ないです。
実は、LLMが文章を作り出す仕組みは、皆さんが子供の頃に解いたことがある「穴埋め問題」と、くじ引きや天気予報でおなじみの「確率」という、とてもシンプルな考え方に基づいています。
この記事では、複雑そうに見えるLLMもシンプルな原理で動いていることを解説します。魔法のようなAIの裏側を覗いてみましょう。

LLMとは?
まず、ここで「AI」と「LLM」という言葉の違いをはっきりさせましょう。
AIは、人間の知能を模倣し、問題解決や判断、学習などさまざまな機能を実現する技術全体を指します。たとえば、音声認識や画像解析、自動運転など、多岐にわたる分野が含まれます。
一方で、LLM(大規模言語モデル)は、AIの中でも特に「言葉」に特化した技術です。LLMは、膨大な文章データをもとに、文章の生成を行います。つまり、LLMはAIの一部であり、文章や会話の分野で人間に近い自然な応答を生み出すことに特化しています。
LLMの学習プロセス
私たちが使用しているLLMはまず「学習」というプロセスを経て作られています。LLMが人間のように自然な文章を生成するには、事前に大量のテキストを読み込み、文章の構造や文法、言葉の使い方を学ぶ必要があります。
普段、私たち人間が文章を作るとき、文法や言葉の使い方は自然に身についているため、意識するのは表現や言葉の選択といった部分です。しかし、コンピューターは最初からその能力を持っているわけではありません。LLMは、人間が無意識に行っているこれらのプロセスを明示的に学習する必要があるのです。
具体的にLLMはどのように学習するのでしょうか。それは大量のテキストデータを読み込み、その中で特定の言葉やフレーズがどのような文脈や位置で使われるかというパターンを認識し、理解することから始まります。言い換えれば、数え切れないほどの文章パターンを記憶し、それらのパターンから規則性を抽出していく作業です。
この学習方法は学校でよく行われる「穴埋め問題」に似ています。穴埋め問題とは、文章の一部が空欄になっていて、その空欄に文脈に合った適切な言葉を入れる課題のことです。LLMも同じように、テキストデータの一部を隠して、その隠された部分に最適な単語を予測するトレーニングを繰り返します。
例えば、「朝、( )を飲んで元気になりました。」という文章を考えてみましょう。ここで空欄に「コーヒー」や「ジュース」という言葉を選ぶことで文章が自然に完成します。LLMは、このような作業を膨大なテキストデータに対して何百万回、何千万回と行い、どの言葉がどのような場面で適切かを体系的に学習していきます。
こうした学習を経て、LLMは人間が直感的に行う言葉選びや文脈理解を習得し、自然で滑らかな文章を生成できるようになります。
確率による予測の仕組み
LLMが次に来る言葉を決める仕組みは、とてもシンプルで「確率」に基づいています。文章中のある位置にどの言葉が現れるかは、前後の文脈から計算される確率で決まります。例えば、「今日はとても( )です。」という文章では、「暑い」や「寒い」、「いい」など複数の候補が考えられますが、LLMはその中で最も自然に見える言葉を、統計的なデータから選び出します。
【図を挿入して3つの単語候補がそれぞれ40%,45%,5%などと示されていることを表したい。一旦claudeで生成してみた。】
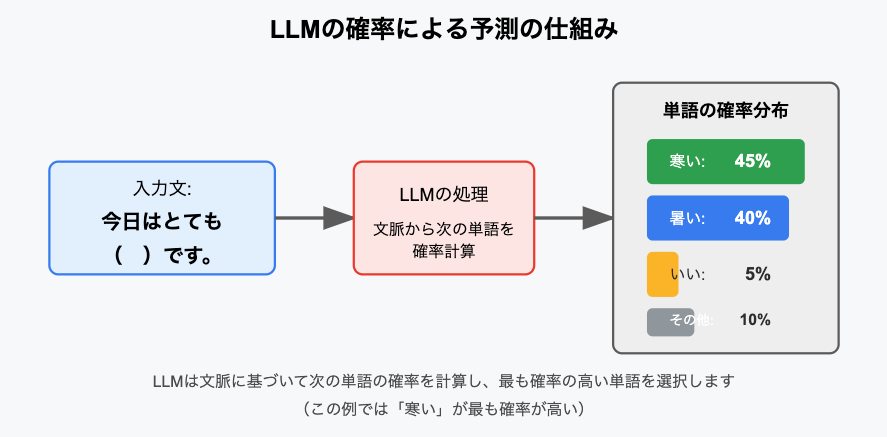
このプロセスは、あくまで膨大なデータに基づいた確率の計算であり、LLM自身が「意味」を理解しているわけではありません。単に、どの言葉が出やすいかを数字で判断しているだけなのです。だからこそ、時には文脈から外れた不自然な答えが返ってくることもありますが、それも確率に過ぎないというシンプルな現実があります。
LLMの活用例
このような仕組みを活かして、LLMは日常生活のさまざまなシーンで利用されています。具体的には以下のような使用例があります。
- チャットボット: ウェブサイトの問い合わせ対応やカスタマーサポートで、ユーザーの質問に対し自然な会話形式で返答します。
- 長い文章作成: ブログやレポート、メールなどの文章作成時に、適切な表現やアイデアを提示してくれるツールとして活用されています。
- 翻訳ツール: 異なる言語間で自然な翻訳文を生成し、文脈に合った訳語を選ぶサポートを行っています。
これらはすべて、LLMが膨大なデータから学習した「穴埋め問題」と、そこから導かれる「確率的な予測」によるものです。
利用する上での注意点

LLMの魅力は、誰でも手軽に自然な文章が作れる点にありますが、いくつかの注意点もあります。
- 情報の最新性: LLMは過去のデータに基づいて予測を行うため、最新の情報や正確な事実が反映されていないことがあります。重要な情報は、信頼できる別の情報源で確認する必要があります。
- ハルシネーション(誤情報生成)の可能性:モデルはあくまで確率に基づいて出力を行うため、実在しない事象や誤ったデータを自信を持って返す場合があります。
- 確率計算の限界: 基本的には統計的な計算に基づいているため、場合によっては文脈に合わない答えが出ることもあります。
- 利用時のルール: 自動生成された文章には著作権やプライバシーなどの問題が伴う場合があるため、利用時にはルールを守ることが求められます。
AIが事実に基づかない情報や存在しない情報をあたかも真実のように生成してしまうことをハルシネーションといいます。特に新しいニュースや専門知識を要する内容では誤りが起こりやすいため、必ず正式な情報源を確認してください。
まとめ
LLMは、その自然な会話能力や多様な応用範囲から、多くの場面で私たちの生活に浸透しつつあります。しかし、その裏にある仕組みは決して魔法のような不可解なものではなく、私たちが子どものころに慣れ親しんだ「穴埋め問題」と、日常的に使われる「確率」という基本的な考え方に基づいて動いています。
有識者が「LLMの回答の全てを信用するのは良くない」というのはLLMの回答が確率に基づいているが故の注意喚起なのです。
これからもLLMは進化を続け、さまざまな分野に影響を与えていくと予想されます。その中で、私たち一人ひとりがその原理と特徴を正しく理解し、賢く付き合っていくことが、AI時代を生き抜くための大切なスキルになるでしょう。
